【解析】
一、单项选择题(共 15 题,每题 2 分,共计 30 分;每题有且仅有一个正确选项)
【第1题】在 Linux 系统终端中,用于切换工作目录的命令为( )?
A. ls
B. cd
C. cp
D. all
答案:B
解析:
ls命令为查看当前目录及子目录;
cd命令为进入/改变目录;
cp为复制文件或目录。
linux中不存在直接以all为名的命令。
【第2题】你同时用 time 命令和秒表为某个程序在单核 CPU 的运行计时。假如 time 命令的输出如下:
real 0m30.721s
user 0m24.579s
sys 0m6.123s
以下最接近秒表计时的时长为( )。
A. 30s
B. 24s
C. 18s
D. 6s
答案:A
解析:
time命令是linux系统的命令,用来测量命令的执行时间,或者调出系统资源的使用情况。例如:
time ls:查看ls命令的执行时间,包括real、user和sys时间。
其中,real用时为命令开始执行到结束时所经历的实际时钟时间,包括了CPU用时和所有其他延迟程序执行因素的和。
CPU用时又分为user和sys两块。user是程序本身,以及程序调用库中的子程序使用的时间;sys是程序直接或间接调用系统服务时CPU的时间消耗。
一般来说,对于单核CPU,这三种时间的相互关系为real > user + sys,但是如果是多核CPU,关系就变成了real ≤ user + sys。
real: 总的运行时间,从命令开始执行到结束的时间,包括等待CPU时间和其他进程时间。
user: 用户CPU时间,即在用户态下花费的时间,不包括用于内核操作的时间。
sys: 系统CPU时间,即在内核态下花费的时间,比如执行系统调用所花费的时间。
秒表计时的时长接近于程序运行的总时间,即real后面显示的时间。
【第3题】若元素 a、b、c、d、e、f 依次进栈,允许进栈、退栈操作交替进行,但不允许连续三次退栈操作,则不可能得到的出栈序列是( )
A. dcebfa
B. cbdaef
C. bcaefd
D. afedcb
答案:D
解析:
栈是计算机科学中的一种数据类型,只允许在线性数据集合的一端(被称为top)进行插入数据(操作名为push)和删除数据(操作名为pop)的运算,是一种先进后出的线性表。
本题要对每个选项逐一分析进出栈的操作。
A选项:a、b、c、d进栈,d、c出栈,e进栈,e、b出栈,f进栈,f、a出栈
B选项:a、b、c进栈,c、b出栈,d进栈,d、a出栈,e进栈,e出栈,f进栈,f出栈
C选项:a、b进栈,b出栈,c进栈,c、a出栈,d、e进栈,e出栈,f进栈,f、d出栈
D选项:a进栈,a出栈,b、c、d、e、f进栈,f、e、d、c、b出栈,连续5次出栈,不符合题意。
该类问题的解题策略为:如果x出栈,那么在x前入栈的元素除了已经出栈的元素,都在栈内。
A 选项dcebfa成立:
| 已出栈序列 | 栈内:栈底…栈顶 | 下一步操作 |
|---|---|---|
| d | a b c | 出栈c |
| d c | a b | 入栈e,出栈e |
| d c e | a b | 出栈b |
| d c e b | a | 入栈f 出栈f |
| d c e b f | a | 出栈a |
| d c e b f a |
B选项cbdaef成立:
| 已出栈序列 | 栈内:栈底…栈顶 | 下一步操作 |
|---|---|---|
| c | a b | 出栈b |
| c b | a | 入栈d,出栈d |
| c b d | a | 出栈a |
| c b d a | 空 | 入栈e 出栈e |
| c b d a e | 空 | 入栈f 出栈f |
| c b d a e f | 空 |
C选项bcaefd成立:
| 已出栈序列 | 栈内:栈底…栈顶 | 下一步操作 |
|---|---|---|
| b | a | 入栈c,出栈c |
| b c | a | 出栈a |
| b c a | 空 | 入栈d |
| b c a | d | 入栈e 出栈e |
| b c a e | d | 入栈f 出栈f |
| b c a e f | d | 出栈 d |
| b c a e f d |
D选项afedcb不成立:
| 已出栈序列 | 栈内:栈底…栈顶 | 下一步操作 |
|---|---|---|
| 空 | 入栈a,出栈a | |
| a | 空 | 入栈b c d e f |
| a | b c d e f | 出栈 f e d c b |
| a f e d c b | 空 |
需要连续5次出栈,才能得到目标序列,不满足“不能有连续3次出栈”,因此D选项不成立。
【第4题】考虑对 n 个数进行排序,以下最坏时间复杂度低于 O(n^2) 的排序方法是( )
A. 插入排序
B. 冒泡排序
C. 归并排序
D. 快速排序
答案:C
解析:
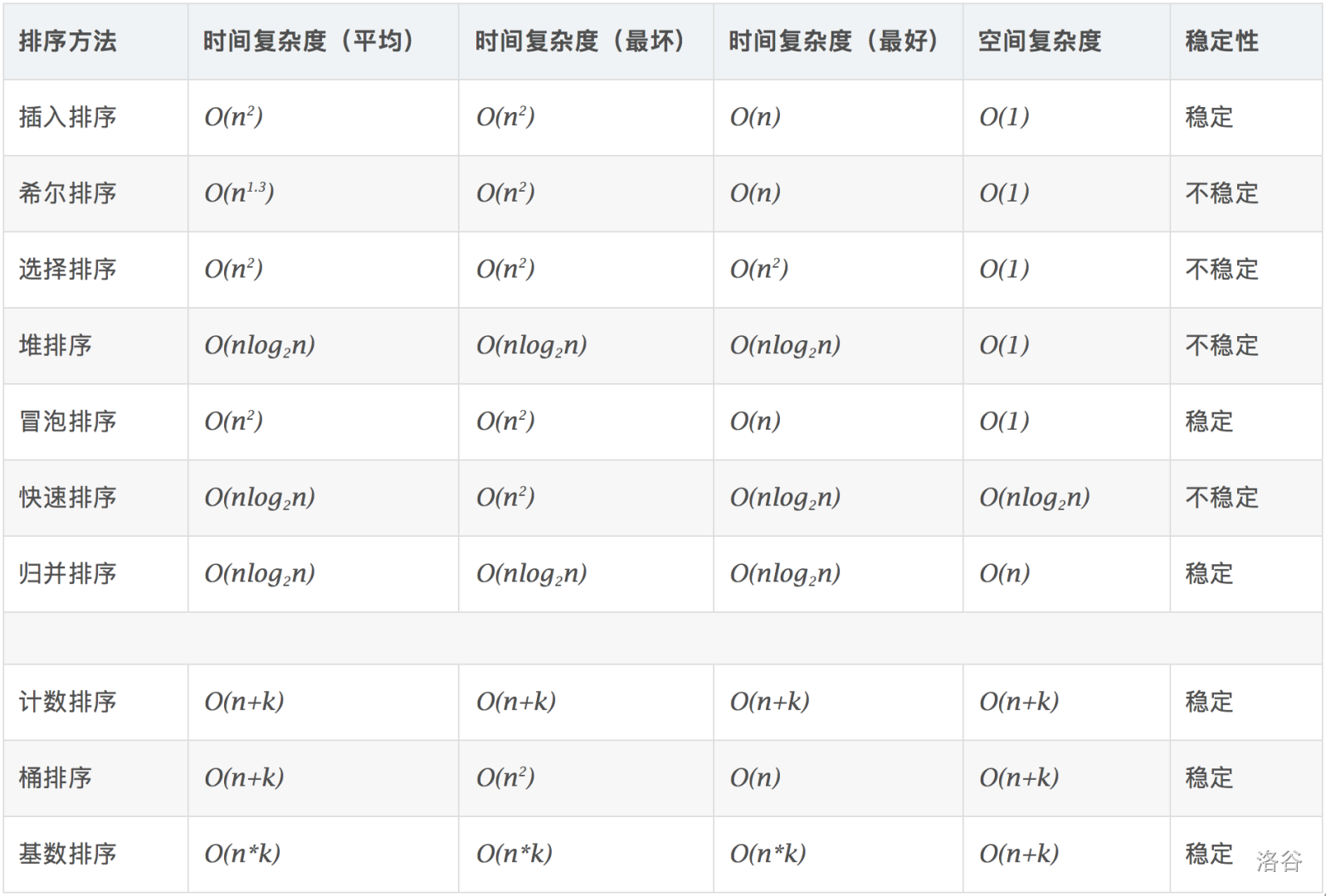
【第5题】假设在基数排序过程中,受宇宙射线的影响,某项数据异变为一个完全不同的值。请问排序算法结束后,可能出现的最坏情况是( )。
A. 移除受影响的数据后,最终序列是有序序列
B. 移除受影响的数据后,最终序列是前后两个有序的子序列
C. 移除受影响的数据后,最终序列是一个有序的子序列和一个基本无序的子序列
D. 移除受影响的数据后,最终序列基本无序
答案:A
解析:首先得了解什么是基数排序。
基数排序是一种非比较的针对正整数的排序方法,基本原理为将所有数字统一为数位相同的数字,通过计算各个数字的键值(key),将要排序的数字反复分配到不同的“桶”中,从而达到排序的目的。
以数组{73,22,8,123,543,21,12,18}为例进行基数排序:
第1步:
将所有的数字都处理为三位数(不用明面处理数据,心理清楚就好),数组变为
{073,022,008,123,543,021,012,018}
第2步:
根据所有数字的个位数,按顺序遍历数组后分别放到编号为0~9的“桶”中;(在具体代码中可以定义数组cnt[10]来存放这些数字)
cnt[1]中有{21};
cnt[2]中有{22,12};
cnt[3]中有{73,123,543};
cnt[8]中有{8,18};
第3步:
按照桶的顺序取出各个数字,排成新的数组,数组变为
{21,22,12,73,123,543,8,18}
第4步:
再按新数组顺序,根据每个数字的十位数,遍历后将数字分别放到编号为0~9的桶中(桶已清空)
cnt[0]中有{8};(表明这个桶存放的是1位数)
cnt[1]中有{12,18};
cnt[2]中有{21,22,123};
cnt[4]中有{543};
cnt[7]中有{73};
第5步:
再次按桶的顺序取出各个数字,排成新顺序的数组,变为
{8,12,18,21,22,123,543,73}
第6步:
按新数组顺序,根据每个数字的百位数,遍历后分置于各桶中(桶已清空)
cnt[0]中有{8,12,18,21,22,73}(都是没有百位的数字)
cnt[1]中有{123}
cnt[5]中有{543}
第7步:
按桶顺序取出数据,最终的数组就是排好序的数组,是
{8,12,18,21,22,73,123,543}
可以发现,在排序的过程中,每个数字的相对位置不会受到其他数字的干扰,因此受影响的数据只会改变它自身的排序位置,而删除该数据后,其他数据的顺序不受影响。
【第6题】计算机系统用小端(Little Endian)和大端(Big Endian)来描述多字节数据的存储地址顺序模式,其中小端表示将低位字节数据存储在低地址的模式、大端表示将高位字节数据存储在低地址的模式。在小端模式的系统和大端模式的系统分别编译和运行以下C++代码段表示的程序,将分别输出什么结果?( )。
A. EF、EF
B. EF、DE
C. DE、EF
D. DE、DE
答案:B
解析:首先解读一下代码:
(1)unsigned x即unsigned int x,是个无符号整型,在内存中占4个字节;
(2)unsigned char为无符号字符型,在内存中占1个字节;
(3)x = 0xDEADBEEF,0x表示将变量x赋值成一个十六进制数。
在学习进制转换的知识中,同学们应该都还记得,1位十六进制数字 = 4位的二进制数,因此这个十六进制数刚好占满了整型的4个字节;
(4)第二行的后半句话,将x类型强制转换为字符型,由于数据类型占的内存变小了,因此会截取x的部分值出来,在内存中会截取低地址内存字节中存放的值;
(5)printf中的“%X”表示以十六进制的形式输出;
接下来根据题意,理解小端模式和大端模式,详情见下图。
图片
根据题意,在小端模式下,*p会取到“EF”,而在大端模式下,*p变量会取到“DE”,因此答案为B。
【第7题】一个深度为 5(根结点深度为 1)的完全 3 叉树,按前序遍历的顺序给结点从 1 开始编号,则第 100 号结点的父结点是第( )号。
A. 95
B. 96
C. 97
D. 98
答案:C
-点击查看答案-
解析:先计算深度为5的完全3叉树有多少个结点:
图片
二叉树的前序遍历顺序为“根左右”,由此推断,三叉树的前序遍历顺序为“根左中右”,因此对结点的编号也按这个顺序进行。
在所有的121个结点中,除了根节点外,其他120个结点会平均分配到根节点的左、中、右子树中,其中,左子树的结点编号为2~41,中子树的结点编号为42~81,右子树的结点编号为82~121,因此题目要找的100号结点在右子树中。
在右子树中,根结点为82,其他三棵子树的结点范围分别是83~95、96~108、109~121,因此100所在的位置为根节点的右子树的中子树中。
接下来可以画图求解:
图片
根据图示,100号结点的父结点为97号。
解析:
图片
- 计算机系统用小端(Little Endian)和大端(Big Endian)来描述多字节数据的存储地址顺序模式,其中小端表示将低位字节数据存储在低地址的模式、大端表示将高位字节数据存储在低地址的模式。在小端模式的系统和大端模式的系统分别编译和运行以下 C++代码段表示的程序,将分别输出什么结果?( )
unsigned x = 0xDEADBEEF;
unsigned char *p = (unsigned char *)&x;
printf(“%X”, *p);
A. EF、EF
B. EF、DE
C. DE、EF
D. DE、DE
答:B
unsigned是4字节32位类型,unsigned char是1字节8位的类型。
把unsigned char类型的指针p设为unsigned类型变量x的地址,*p即为x变量的低8位数据。
如果小端模式,低位字节存储在低地址,0xDEADBEEF最低位一字节保存的数据是EF。
如果大端模式,高位字节存储在低地址,0xDEADBEEF最高位一字节保存的数据是DE。
注意,字节内部数据的先后顺序不会发生改变。
- 一个深度为 5(根结点深度为 1)的完全 3 叉树,按前序遍历的顺序给结点从 1 开始编号,则第 100 号结点的父结点是第( )号。
A. 95
B. 96
C. 97
D. 98
答:C
树一共5层,每层结点数分别为1,3,9,27,81。
1层满三叉树共1个结点
2层满三叉树共4个结点
3层满三叉树共13个结点
4层满三叉树共40个结点
按照前序遍历顺序先遍历结点1的第一个子树,该子树是4层满三叉树,共40个结点。遍历第二个子树,也是4层满三叉树,共40个结点,因此1的第三个孩子的编号为82。
结点82的第一个子树为3层满三叉树,共13个结点。
82的第二个孩子编号为96。96的第一个孩子编号为97。97是第5层的结点,97的三个孩子编号分别为98,99,100。
因此100的父结点编号是97。
以下图中x node:y,意思是子树根结点编号是x,该子树共有y个结点。单独一个数字就是结点编号。
【参考】
参考:https://blog.csdn.net/lq1990717/article/details/141991949
参考:https://www.cnblogs.com/Rainy7/p/csp-s-2022-first.html
参考:https://mp.weixin.qq.com/s/QRzazMOumU1AEQwuMneoDQ
参考:https://mp.weixin.qq.com/s/Pj1UVS2XJc6tyHiWqGMjRQ
参考:https://mp.weixin.qq.com/s/1g4qvA119A6p0Zsq9YBXeQ
参考:https://mp.weixin.qq.com/s/5ojc5GM8yEB9xUn9TN_whg
参考:https://mp.weixin.qq.com/s/xy3Bf0lovsjkZBI5NwTEhw
参考:https://mp.weixin.qq.com/s/HQ3CPzwsYoTFhYJssjluxw
参考:https://mp.weixin.qq.com/s/f_fKE64FsYx3nUto4gnMQg
参考:https://mp.weixin.qq.com/s/-bojOE8ynau2MbzKjWg0XA
参考:https://mp.weixin.qq.com/s/7knSpcpwBUwRaAjCiy9OOg